
本文内容选自中国 DevOps 社区年会 · 2019 年会,苏宁金融孙捷老师分享的《支撑万亿交易量的苏宁金融紫金大盘 AIOps 平台架构设计及实践》实录。
大家下午好!非常荣幸今天有这个机会跟大家一起交流 AIOps 的话题。先简单做个自我介绍,我先后就职于 IBM 和苏宁金融,我所在的技术管理中心负责苏宁金融 1000 多名研发人员的技术方面的管理工作。比如系统规划和架构管控、技术规范的制定和推广、以及 DevOps 和 AIOps 方面的事情。

我今天分享的内容包括 4 个部分:首先是回顾一下苏宁金融的发展历程,以及技术运营能力的演进路线;介绍完这个背景后,分享一下我们的技术运营平台紫金大盘的架构设计,第三个部分介绍我们的落地实践;最后聊一聊过程中的心得体会。

先介绍一下苏宁金融的发展历程。
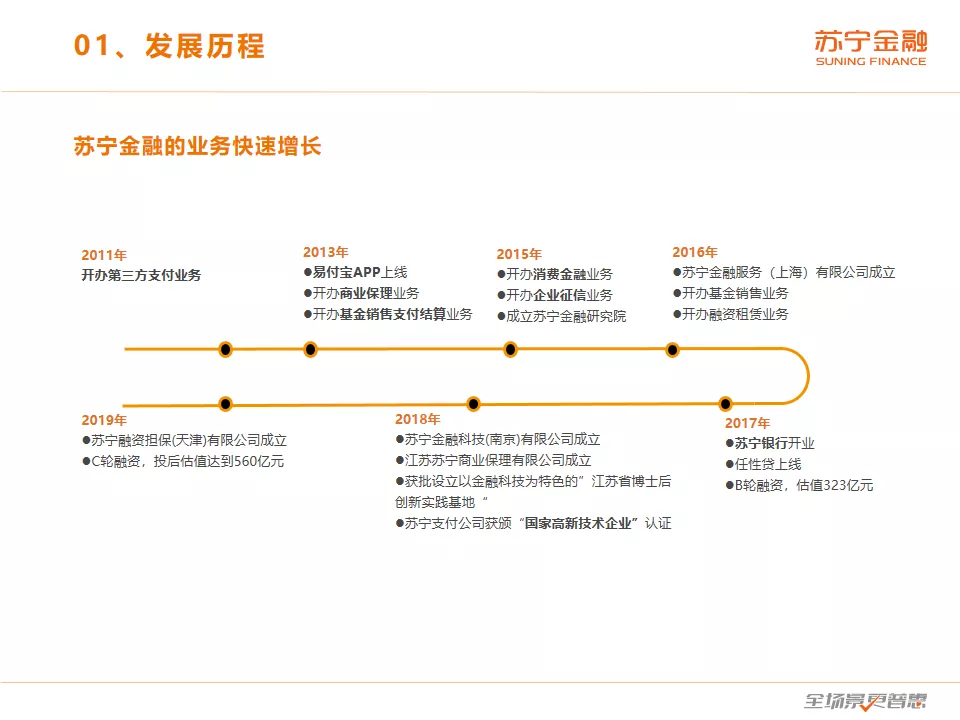
苏宁金融从成立于 2011 年,从第三方支付开始做起,主要服务于苏宁易购的电商场景,到了 2013 年的时候开办商业保理和基金销售支付结算,2015 年开办消费金融和企业征信业务,2016 年开办了基金销售业务和融资租赁业务,并成立上海研发中心,2017 年苏宁银行开业,现在是 2019 年已经 C 轮融资,估值 560 亿,这个过程中整个苏宁金融的业务是快速增长的,交易量从百亿的级别增长到万亿级,这对我们的技术运营能力提出了新的挑战。

首先我们的系统越来越庞大和复杂,苏宁金融达到了 1000+ 的系统,5W+ 的服务器。而整个苏宁易购集团现在是 4000+ 的系统,27W+ 的服务器。如此庞大的系统,带来了高昂的运维成本,我们投入在设备上的成本 34 倍于运维人力成本,因为设备投入的成本是一次性的,但是人力成本会随着时间的推移不断增加,我们研发团队有 30% 的人力投入在运维。我们的运维能力也得到了挑战,生产环境发生的 70% 的严重问题都是人导致的,而且问题的感知和定位速度往往要 12 个小时。大家知道,线上服务每一分每一秒都会影响公司的财务指标,生产故障会给公司和用户的利益带来直接的损害。
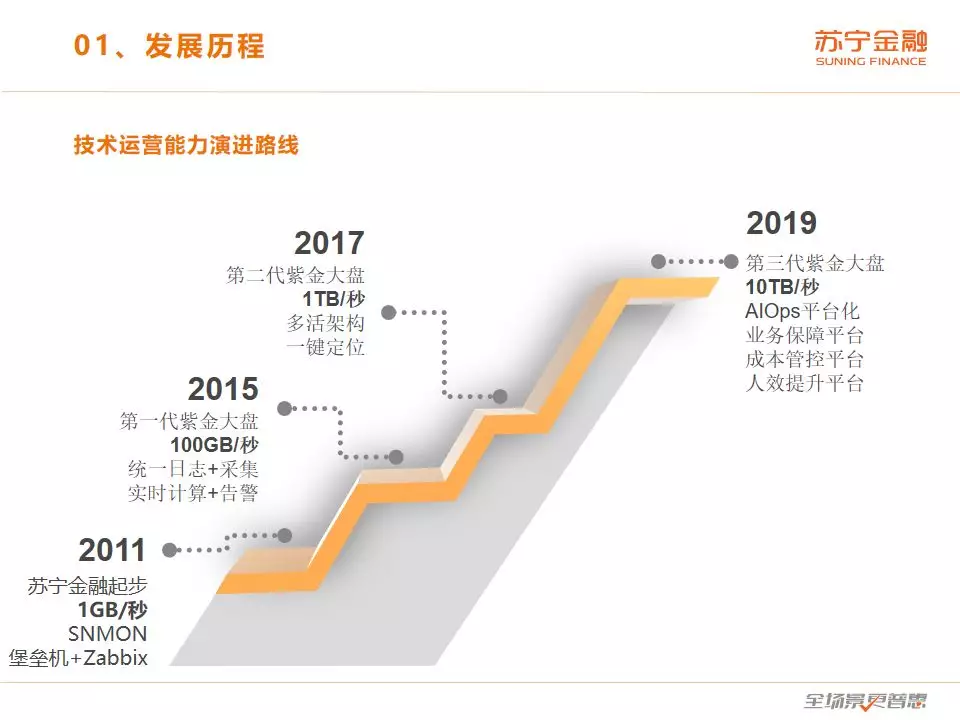
这是我们的技术运营能力的演进路线,2011 年苏宁金融刚起步的时候,是一体式架构,这个大家都很类似,都是从一体式架构起步,日志量是每秒 1GB,监控手段是 SNMON,还有堡垒机和 Zabbix。2015 年的时候,做了一次比较大的重构,这个时候做了微服务的拆分,系统规模增长了将近百倍,这个时候研发了第一代的紫金大盘,那个时候的日志量是每秒1GB左右,也增加了一百倍。我们通过统一日志的格式、统一的采集,还有统一的实时计算和告警做系统监控。到了 2017 年的时候,由于出过严重的事故,对业务连续性要求更高了,这个时候把系统的多活能力建设提到了很高的地位。我们 2017 年开始做双活,做了双活以后,同时有2个机房可以提供服务,原有的紫金大盘的架构就不能满足多活的要求了,所以紫金大盘也做了多活架构改造。另外这个时候的日志量达到了每秒 1TB 左右,为了便于快速定位和解决业务问题,我们做了一键定位平台,可以根据业务单号或者会员号一键定位业务链路的故障,并给出解决方案。
到了 2019 年,交易量已经过万亿,这个时候我们开始往第三代紫金大盘的方向做,现在业务量达到每秒 10TB 左右,比 2017 年又有十倍的增长,我们现在是做 AIOps 平台化,这块主要是有业务保障、成本管控、人效提升三个方向。

接下来我介绍一下我们第三代紫金大盘的架构设计。
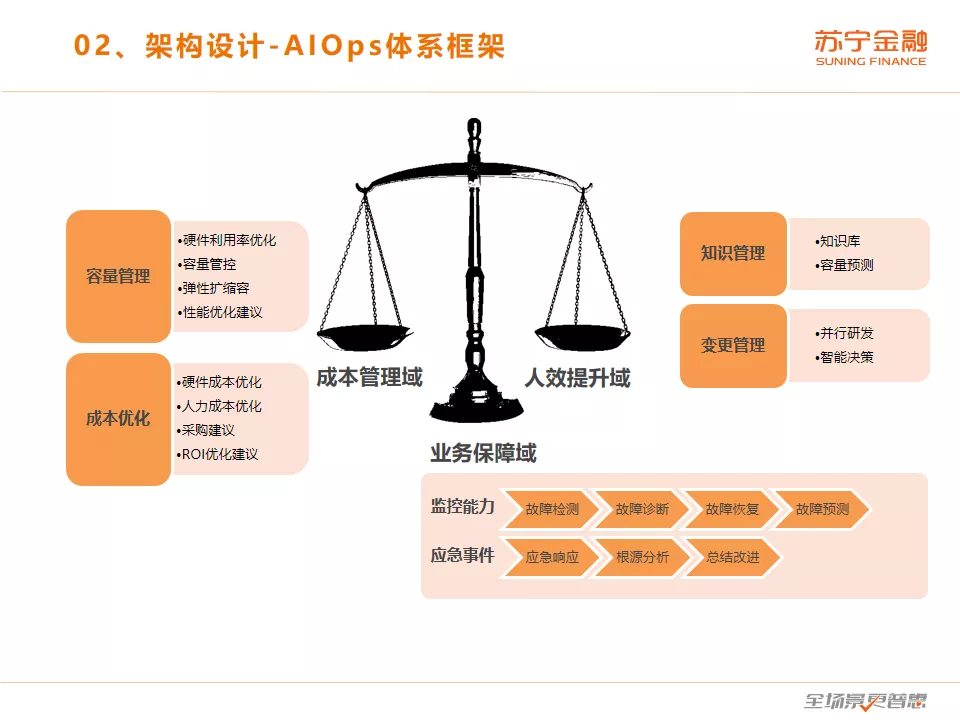
先介绍一下 AIOps 的体系框架,大家都知道其实技术运营是属于 DevOps 中的一个领域。DevOps 还有其他的领域,比如说持续交付、敏捷开发管理,还有应用设计、组织架构、安全管理方面。而 AIOps 其实是技术运营的高阶实现。这块有三个领域,我用了一个天平的形象来表达。我们的根基还是业务的稳定性,所以说业务保障域是在最下面,是一个基座。没有业务稳定这个基础的话,成本管理和人效提升都是空谈。业务稳定的基础上,成本管理和人效提升是一个相互平衡的关系。
业务保障域首先是监控能力,这是最基础的。包括对故障的检测、诊断、恢复、预测,故障预测是基于前三步积累下的历史经验,总结出故障的模式,从而进行预测。其次是应急事件的管理,我们有一套快速的应急响应机制,在生产故障发生时把大家调动起来,集合最大的力量解决生产的问题。生产问题解决掉以后是事件根源的分析,也就是事后的总结,分析出根本的原因,最后做总结改进。
成本管理域也是两块,一块是容量管理,容量管理首先是硬件利用率优化,这是我们今年重点做的这块,现在来说我们整体的利用率不到5%,其实是巨大的浪费。其次是基于容量的预测做容量的规划和管控工作。最后是弹性的扩缩容以及性能的优化建议。
第二块成本优化主要是硬件成本优化、人力成本优化、采购建议,我们采购硬件的时候,如果提前采购了,用不上也是一种成本的浪费,如果采购慢了会影响业务发展,这也是需要智能化的。还有投入产出比的优化建议,这个是结合人力成本和业务的KPI指标来做。
提升人效域,首先是运维的知识库,知识库可以节约运维人员的学习成本,基于知识库可以做容量预测,提高预测的效率。
变更管理方面,并行研发这个刚才刘超老师也讲了,现在苏宁金融的测试环境已经可以做到一键创建测试环境,随时满足并行研发、并行发布的要求。还有智能决策,我们现在的运维决策基本上都是根据人的经验做,但是人是会流失的,知识也是会流失的,如果我们把这些知识固化到系统里面智能的做决策,也是可以提高效率的。
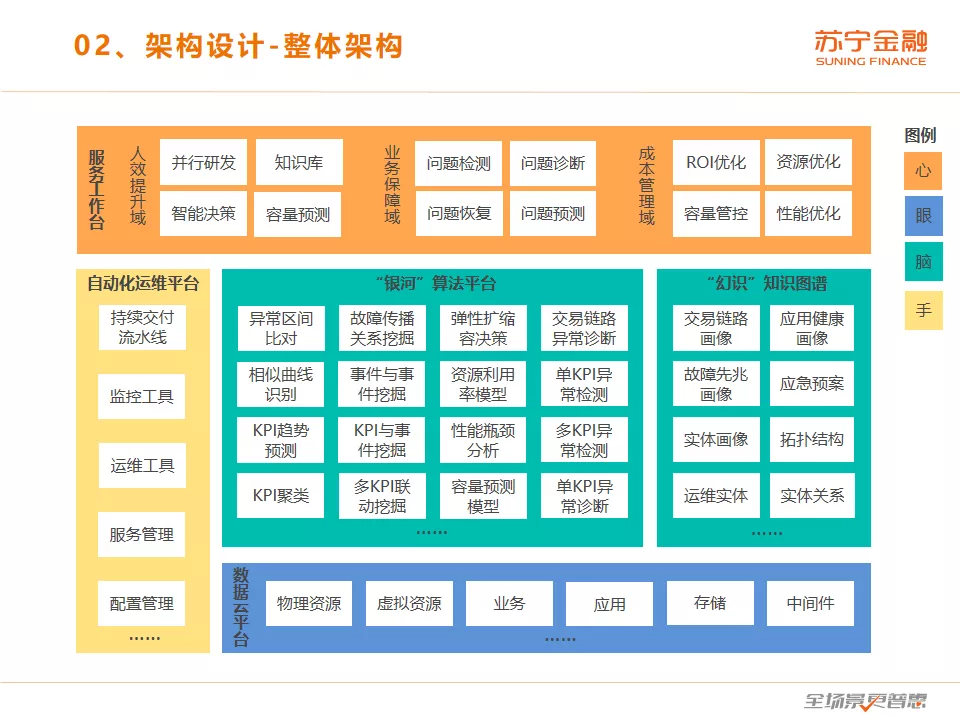
这个是我们紫金大盘的整体架构,分为四个部分。“心”是服务工作台,其职责是协调“眼、脑、手”提供的中后台能力适配终端用户需求,包括人效提升、业务保障、成本管理三大场景。“眼”是数据云平台,把包括物理资源、虚拟资源、业务、应用、存储、中间件在内所有运维实体的整个生命周期的数据都统一汇聚在数据云平台并进行数据管理和治理。“脑”根据“眼”看到的信息进行快速决策,并给“手”发出执行指令。包括负责存储静态知识的“幻识”知识图谱和负责动态决策的“银河”算法平台两个部分。“手”是自动化运维平台,用自动化脚本操作替代人工操作,包括配置管理、服务管理、运维工具、监控工具、持续交付流水线等。这是一个“心眼脑手”四位一体的 AIOps 智能运维平台。
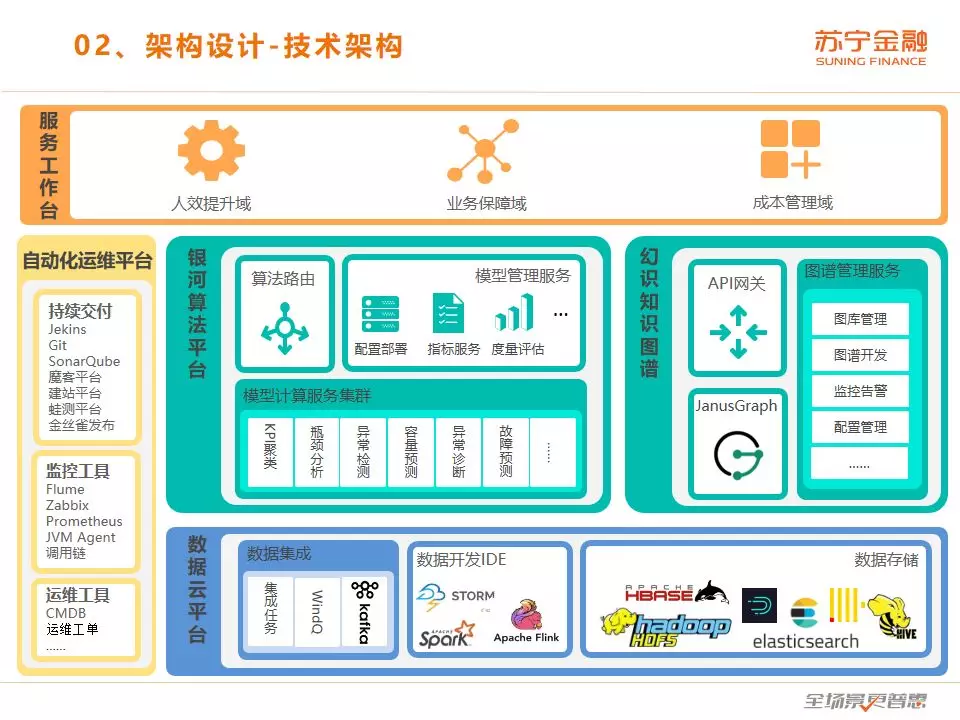
这是我们的技术架构,我们的数据云平台分为三大模块,第一个模块是数据集成,数据集成负责采集数据,可以开发数据集成任务,例如从数据库直接捞取数据。第二个模块是数据开发IDE,提供了数据开发的可视化操作和编辑的能力。可以通过所见即所得的方式来编辑数据开发的任务,例如数据的加工,还有数据的计算。第三个模块是数据存储,我们封装了多种中间件,HDFS、ES、HBASE、Hive、Druid、Clickhouse 等。
算法平台也是分为三部分,第一部分是算法路由,它的职责是负责把前端的不同业务请求分发到后端的模型计算服务集群上去,这个模型计算服务集群一般根据业务的相似性,或者算法技术的相似性做一个集群的分割,满足不同的算法服务要求。模型的管理,可以提供统一的模型部署、配置功能,以及模型准确度的度量、评估功能。但是现阶段模型的训练是在我们公司另外一个平台上。
幻识知识图谱同样分为三个部分,首先是以 JanusGraph 作为基础的知识图谱数据库,另外还有图谱管理服务,提供了图库管理、图谱开发、监控告警、配置管理功能,通过统一的 API 网关提供服务。
自动化运维平台就不详细介绍了。
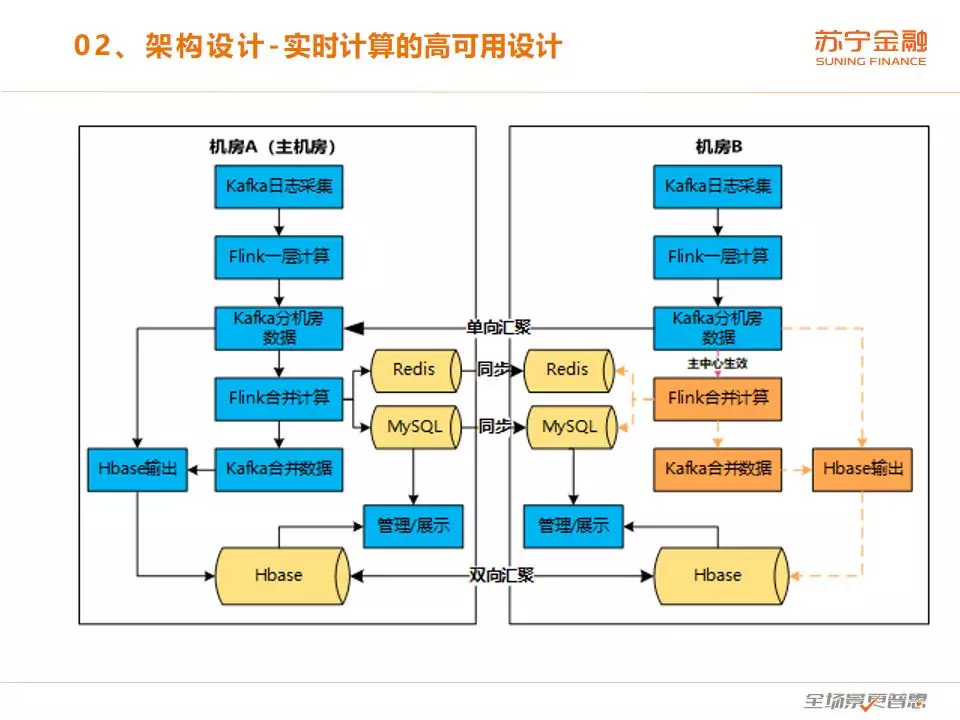
再讲一下我们实时计算的高可用设计,这是 2017 年做多活改造的时候设计的。假设有两个机房,一个 A,一个 B,假设 A 是主机房,正常流程是走的蓝色路线,Kafka 做日志的采集,Flink 做一层计算,Kafka 汇聚分机房的数据,Flink 做多机房合并计算。当机房宕机的时候,主机房自动切换到 B 机房。右边橘色的流程就会苏醒,所有的合并计算在 B 机房计算,保证了双活。
下面介绍一下落地案例。

先介绍一下业务保障域,一个比较经典的智能问题问题诊断场景。

在互联网零售业务中,为了吸引新用户注册或者增加老用户的活跃度,经常会做支付促销让利活动,但是同时也吸引了逐利而来 “羊毛党”、“黄牛党”和“灰产大军”等非正常用户。有限的营销资源如果被非正常用户大量占用,会导致正常用户无法参与营销活动,从而给公司带来营销资源的浪费以及未来收入的损失,所以公司会针对各种营销活动进行风险控制,对疑似非正常用户的请求进行拦截。一般而言 “营销活动风险拦截量”这个 KPI 会在一个稳定的区间内波动,当这个 KPI 突然上升可能是大量正常用户被拦截影响营销活动的效果,当这个 KPI 突然下降可能是风险控制模型失效未正常拦截非正常用户的请求。为了尽快诊断出问题的根因,以便于执行针对性的应对措施,运维部门组建了一个固定的 4 人数据分析小组, 每日至少花费 4 个小时使用 Excel 等工具进行KPI相关数据的人工分析,成本高昂,工作效率低且容易出错,急需智能诊断能力。
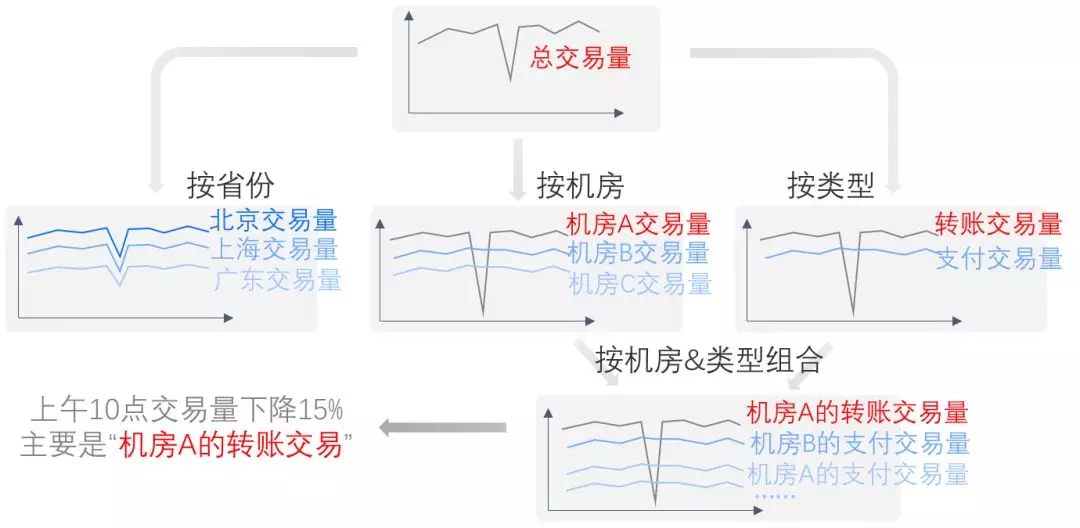
当某个总指标发生异常的时候,我们怎么定位原因?当总指标发生变化的时候,一定是由下面的子维度导致的,这叫做涟漪效应(REF:Yongqian Sun, Youjian Zhao, Ya su, et al., “HotSpot:Anomaly Localization for Additive KPIs withMulti-Dimensional Attributes”, IEEE Access, 2018.),在这个图中总交易量发生变化是因为机房和交易类型 2 个维度发生了突变,导致总指标下降。
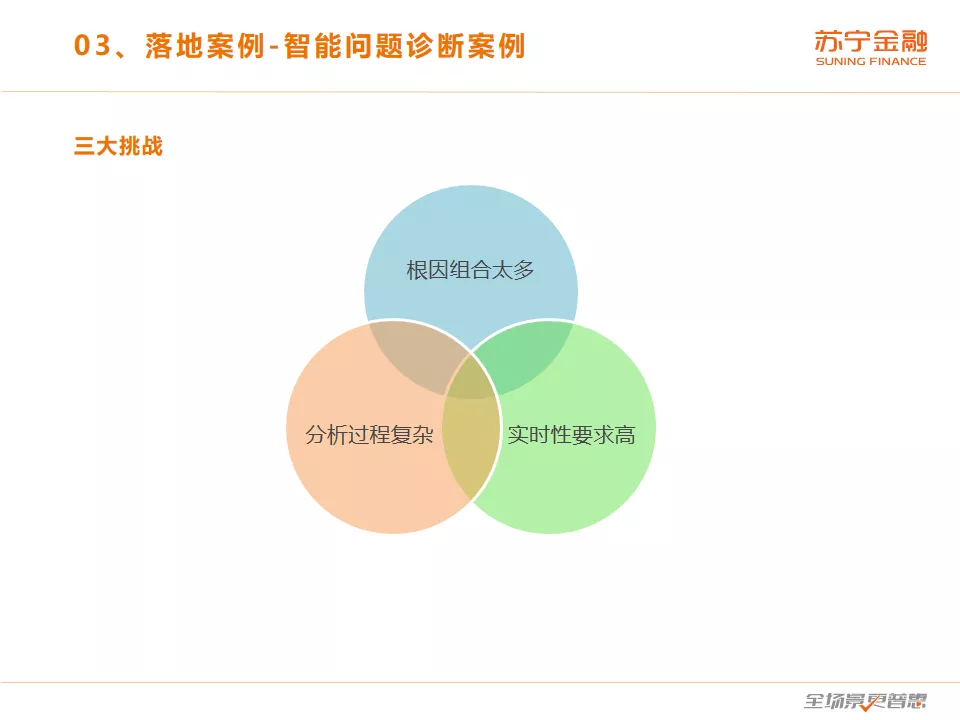
这个案例有三大挑战,首先是可能的根因组合太多,导致搜索的空间过大难以用常规的专家经验和规则分析问题根因。其次是实时性要求高,当问题发生时需要从海量的属性组合中快速找到到根因。最后是根因定位分析的过程复杂,根因分析不是一个简单的分类或者回归问题,输出的根因是一个维度不定的集合,不能用常规的机器学习算法来解决。
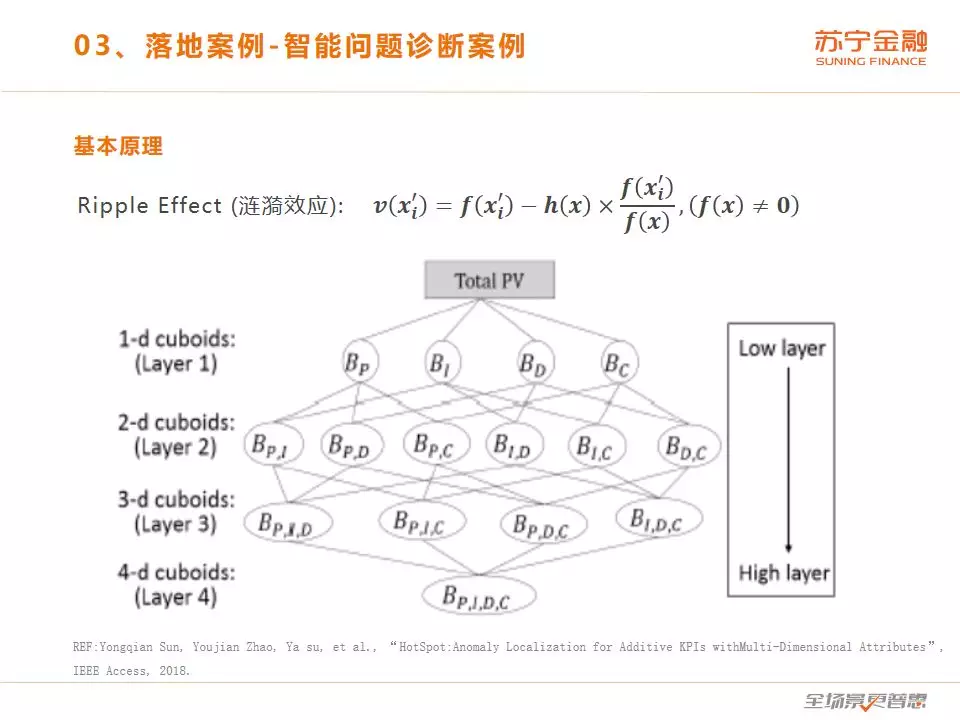
KPI 通常拥有多个属性,以“营销活动风险拦截量”这个 KPI 为例,假设其属性包括手机城市、证件城市、IP城市、营销活动 4 个属性,每个属性都有不同的取值范围。我们可以针对每个不同的属性组合记录一段时间内(比如:每分钟)的 KPI 值,例如:(手机城市=北京,证件城市=上海,IP 城市=福建,营销活动=首单立减),这是一个 4 维的 KPI 值。由于 KPI 值具有可加和特点,这些细粒度的 KPI 也可以被聚合为粗粒度的属性组合。例如,手机城市=北京,证件城市=上海,IP 城市=福建,其他属性不做限制,这样的 KPI 可以被表达为(手机城市=北京,证件城市=上海,IP 城市=福建,营销活动=*)其中 * 是通配符,这是一个 3 维的 KPI 值。基于不同的聚合程度,我们将元素分类为不同层次的数据立方体,从低层到高层维度越来越高,元素的数量变得越来越大,如果元素的数量有 n 个,那么可能的根本原因就有 2n-1 个。
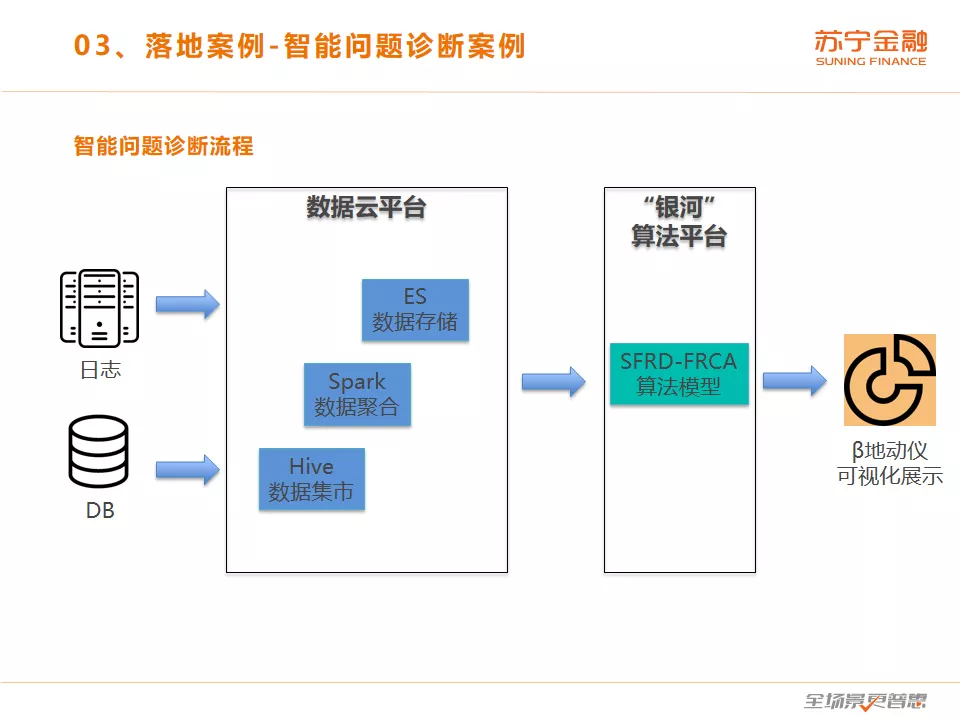
我们的算法流程是这样的,首先来自各类运维实体(物理资源、虚拟资源、业务、应用、存储、中间件)的原始明细数据被数据云平台汇聚存储在 Hive 数据集市中;然后 Spark 把原始明细数据按照运维人员关注的维度聚合成细粒度的 KPI 数据并存储在 ES 中;当用户使用 β 地动仪进行根因分析操作时,部署在“银河”算法平台的 SFRD-FRCA(SuningFinanceR&D-FastRootCause Analysis)算法模型即根据用户的指令查询 ES 中的 KPI 数据并进行智能根因分析,最后将分析结果通过β地动仪可视化给用户。
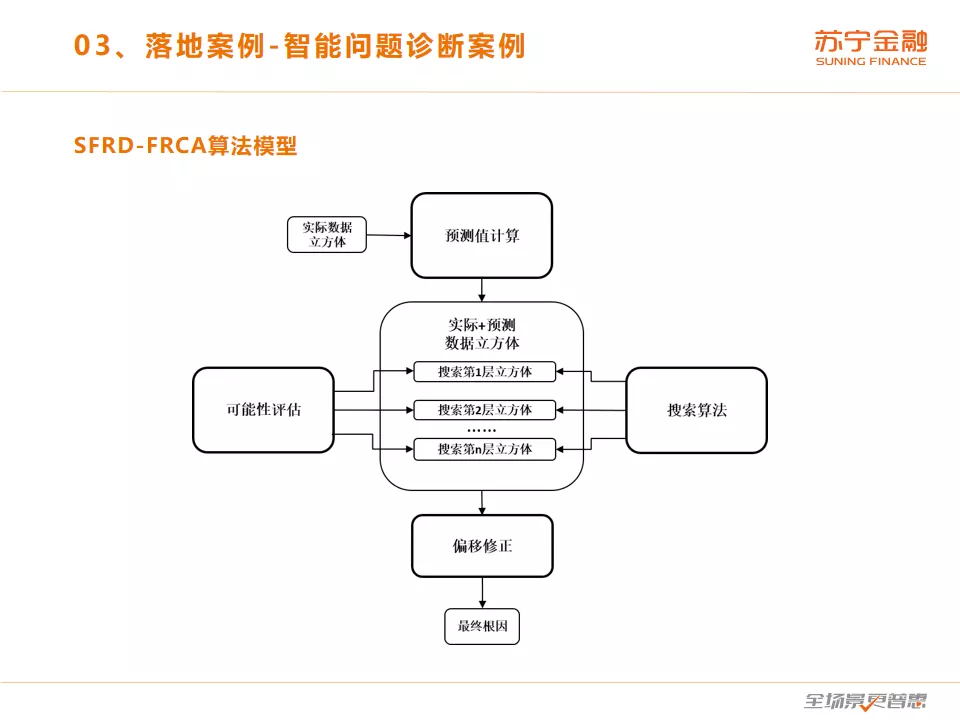
这是核心的 SFRD-FRCA 算法模型。可分解为 4 个关键过程,首先预测值算法根据 ES 中存储的某个时间点的实际数据立方体计算该时间点的预测数据立方体,并输出;然后使用可能性评估算法和搜索算法从低层到高层逐层计算每个根因组合的可能性得分并根据每个根因组合的可能性得分对搜索空间进行搜索,得到每层的最佳根因组合。最后将搜索出来的每层最佳根因组合做偏移修正并返回修正后的最终根因。
下面把这四步一一介绍一下。

首先是预测值的计算。预测值计算的目标是根据 ES 中存储的某个时间点的实际数据立方体计算该时间点的预测数据立方体,并输出作为后续流程的输入。由于该场景对实时性的要求很高,所以要求预测值算法不仅有稳定的准确率表现还要有较低的时间复杂度。经过大量实验比对 ARIMA(整合移动平均自回归)、EWMA(指数加权移动平均法)、Prophet(Facebook 的时间序列预测算法)的实际效果发现。ARIMA 算法对于单独的 KPI 预测效果比较好,但是对大量不同的 KPI 的平稳性难以度量,存在一定的误差。EWMA(指数加权移动平均法)算法时间复杂度低、表现稳定,但是灵活性稍差,存在短期噪声。而 Prophet(Facebook 的时间序列预测算法)算法基于所有历史数据做训练结果精度较高,但是在不同的 KPI 上表现差别较大,且逐点计算的速度较慢。所以最终决定采用时间复杂度最低的 EWMA(指数加权移动平均法)算法,并根据预测区间进行滤波,去除波动较小或者与总体趋势相反的波动噪声,提升预测效果。

可能性评估算法的目标是根据数据立方体的实际值与预测值之间的差异用可能性评价公式计算根因可能性得分,以便于后续的搜索算法根据可能性得分来搜索最优根因组合。可能性评价公式可评判出一组结果是根因的可能性,得分越高则是根因的可能性越高,得分介于 0 到 1。可能性评价公式需要计算向量距离,在实际项目中我们通过大量实验发现只用单一的距离函数在特定根因组合场景下会表现不佳,而采用多种距离函数进行组合计算可以获得更加稳定的表现。最终我们的距离函数采用余弦相似度、Pearson 相关系数、KL 散度、JS 散度进行组合计算,将不同距离函数计算出的 Score 进行加权合并。
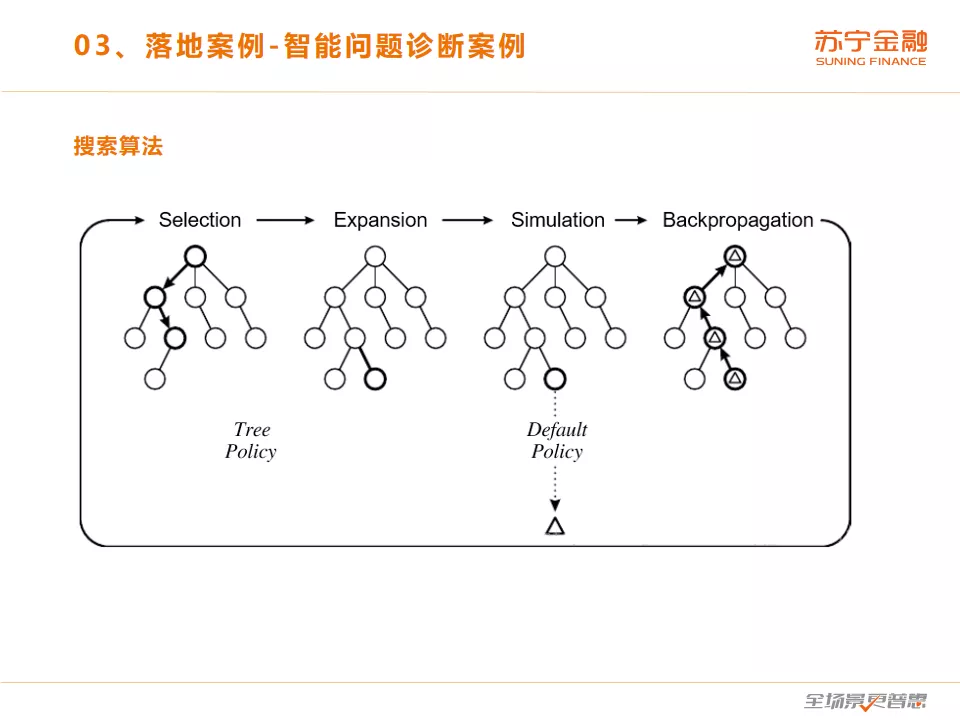
搜索算法的作用是根据根因的可能性得分进行根因搜索,搜索出最有可能的根因组合。为了应对这个场景中巨大的搜索计算量需要有效且高效的搜索算法。我们的思路是采用一些已知的擅长巨大搜索计算量的高级算法,而不是重新人工探索开发算法。受 Alpha Go 在游戏中成功采用MCTS的启发,我们采用 MCTS 算法进行搜索,在限制了搜索次数的情况下,搜索出可能性得分最高的元素组合。同时设置了可能性得分的上阈值和下阈值,当搜索出的根因组合的可能性得分大于上阈值时,终止搜索返回结果。
然而即使对于 MCTS 算法来说, 的时间复杂度也不是一件容易的事。为了减少搜索计算量,我们应用了分层修剪策略。基本思想是,在搜索较低层后,搜索算法会在更高层中修剪一些不太可能是根本原因的元素。简单来说,就是如果父元素具有非常低的可能性得分,则每个子元素不太可能是根本原因,因此可以被修剪。这种方法在思路上与关联规则挖掘中的频繁项集算法非常相似,我们将修剪方法称为分层剪枝,因为其修剪策略使用层次结构信息。

偏移修正算法的目标是对上一步计算出来的每层最佳根因组合做偏移修正并返回修正后的最终根因。我们在实践中发现,由于算法本身结构的原因,可能会输出可能性得分相近的多个答案,这时候需要一种决策机制来选择最终答案,确保最终的答案尽可能的准确,通过大量实验这里我们最终选择了最简单有效的奥卡姆剃刀原则,当多个根因得分相近时,选择更简约的根因,将层数和根因组合数加入公式,层数越深或者根因组合越多,最终得分则越低。
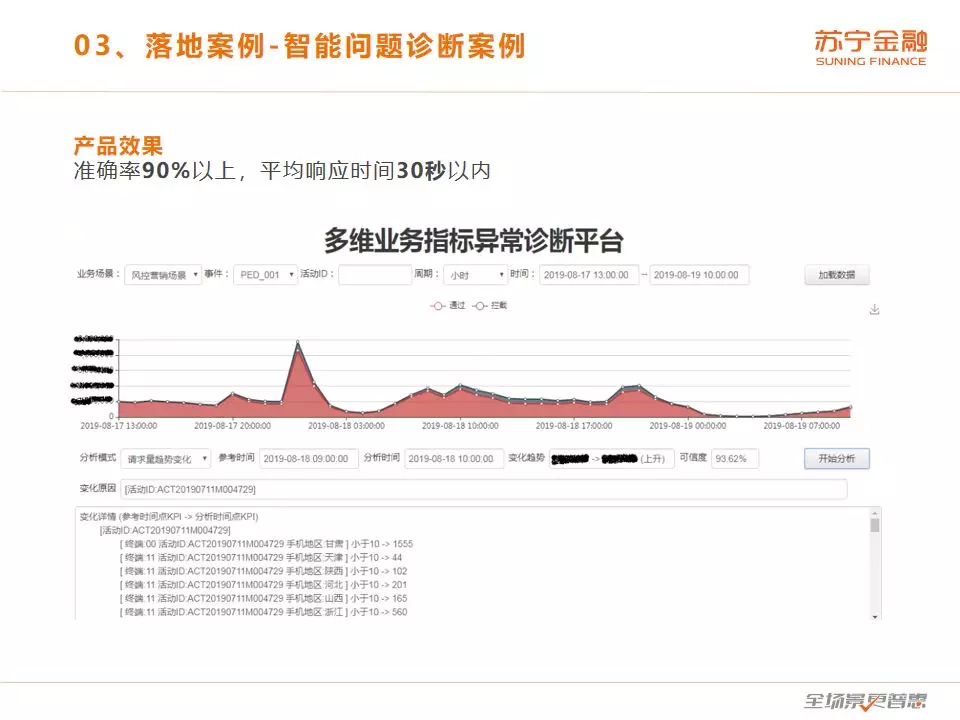
应用在实际场景中时,SFRD-FRCA 算法模型的准确率在 90% 以上,平均响应时间在 30 秒以内,表现非常优秀,已经大规模应用于苏宁的互联网金融领域。在“营销活动风险拦截量”KPI的根因定位场景中,问题的诊断时间从4小时以上降低到 10 秒,诊断准确率达到 99%,且不再需要固定数据分析小组负责专项工作,提高了工作效率的同时节约了大量人力成本。

第二个实例是我们的硬件成本管控,这块是今年做起来的。
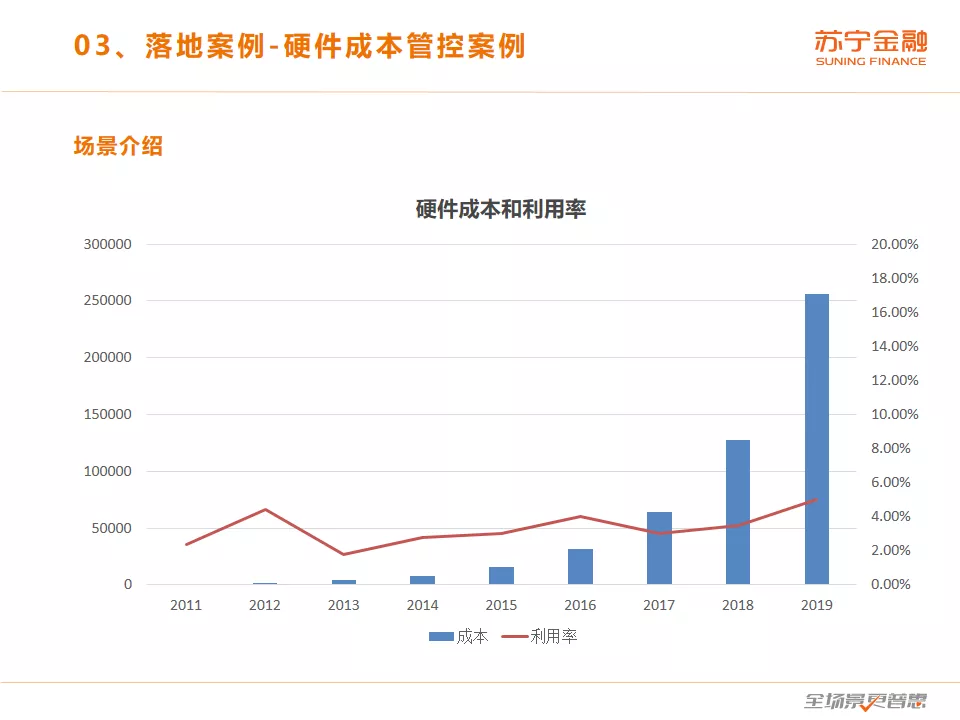
我们每年的成本都是呈一个翻番的形式增长,但是我们的硬件资源利用率始终是保持在很低的水平。之前业务的稳定性是第一的,为了保障业务的稳定会不计成本的扩机器,并且业务刚开始爆发式增长的时候,很少会关心成本,从而导致了这个现状。
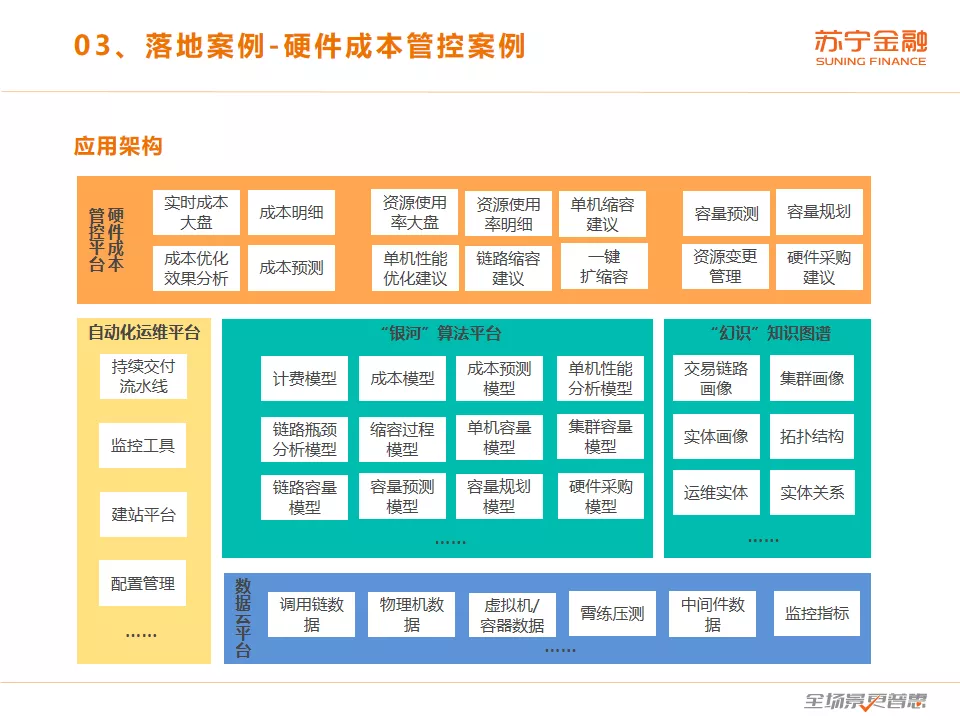
这个是我们硬件成本管控平台的应用架构图,属于 AIOps 平台整体架构的一部分,不过里面的东西是跟硬件成本相关的。比如说我们的数据云平台里面的数据主要是调用链的数据,还有压测平台的数据以及应用的监控指标。知识图谱里面,比较关注运维实体,实体之间的关系,实体的画像、交易链路的画像等。
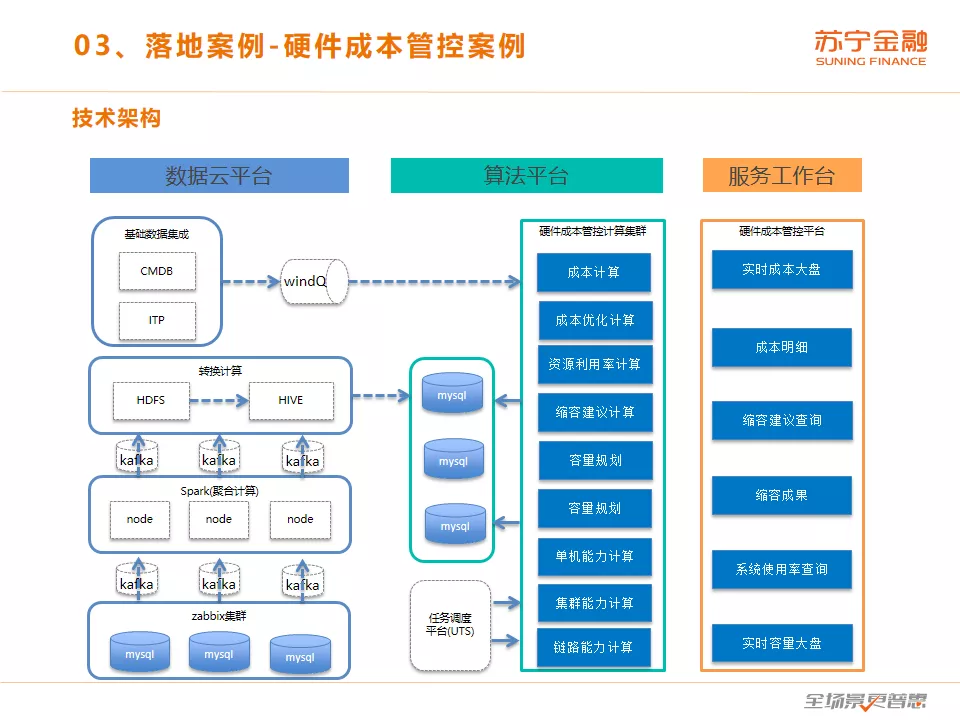
这是硬件成本管控平台的技术架构图,来自运维实体数据和监控指标数据被汇聚到数据云平台,经过算法平台硬件成本管控计算集群的分析和处理由,由服务工作台提供各类成本管理功能。

这是产品效果的截图,图中是缩容效果分析功能,我们可以看到每个月缩容节约了多少费用,每个月节约多少硬件资源。

2019 年截止目前已经节约了硬件成本 15%,而苏宁金融集团的硬件成本费用是亿级的,所以大家可想而知这项工作的价值。另外我们的开发小组只有一个产品经理,四个开发,所以投入产出比是非常高的。明年这个产品计划为全集团服务,预计节约的成本可以上亿。

最后介绍一下人效提升域的案例。
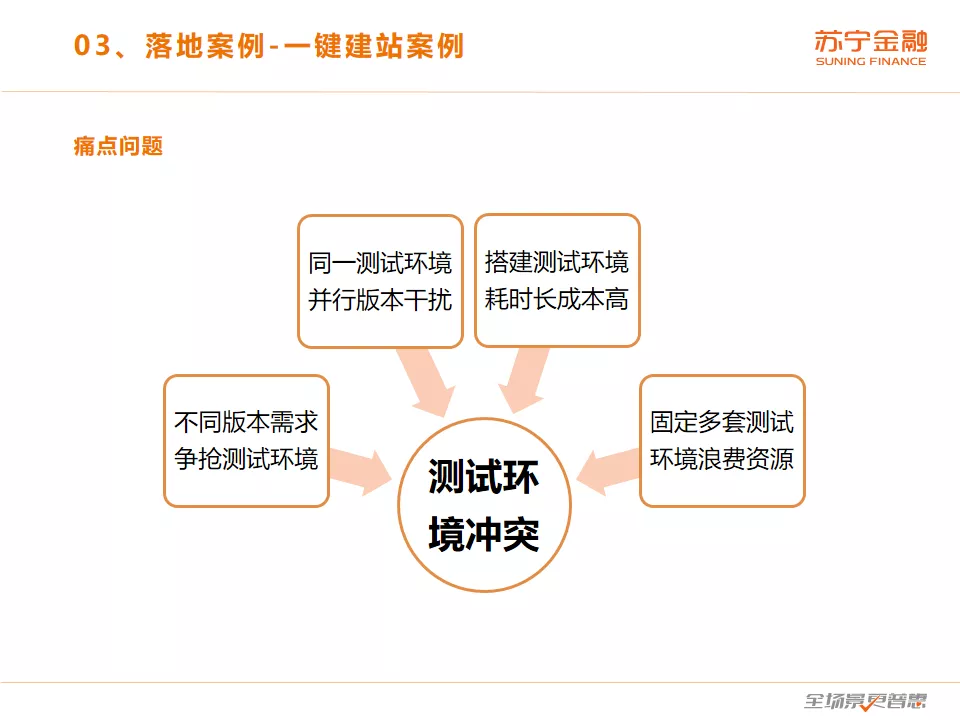
相信各个研发团队都经常遇到过类似的场景:
- 不同版本的需求争抢测试环境,系统的测试环境只有 2 个(SIT、PRE),当一波需求高峰来临,上线时间还重叠,这个时候怎么办呢?排优先级,牺牲掉相对不重要的需求(其实也是很重要的需求),这样可能会带来商业价值的重大损失。
- 同一测试环境的并行版本会互相干扰,比如在消费者中心和中台中心的 PRE 环境上都有版本在开发测试,而且是不同上线时间的版本,那么不同版本的发布就会对测试产生干扰,测试结果受发布影响就会不稳定。
- 搭建测试环境耗时长成本高:测试环境不足,那么安排人搭建个环境吧?往往要数百人天,时间要长达几个月。
- 固定多套环境浪费资源:咱们并不总是需要 3 套,4 套测试环境,当一波业务需求高峰过去,多套测试环境就成了浪费,此时拆也不是,不拆也不是。
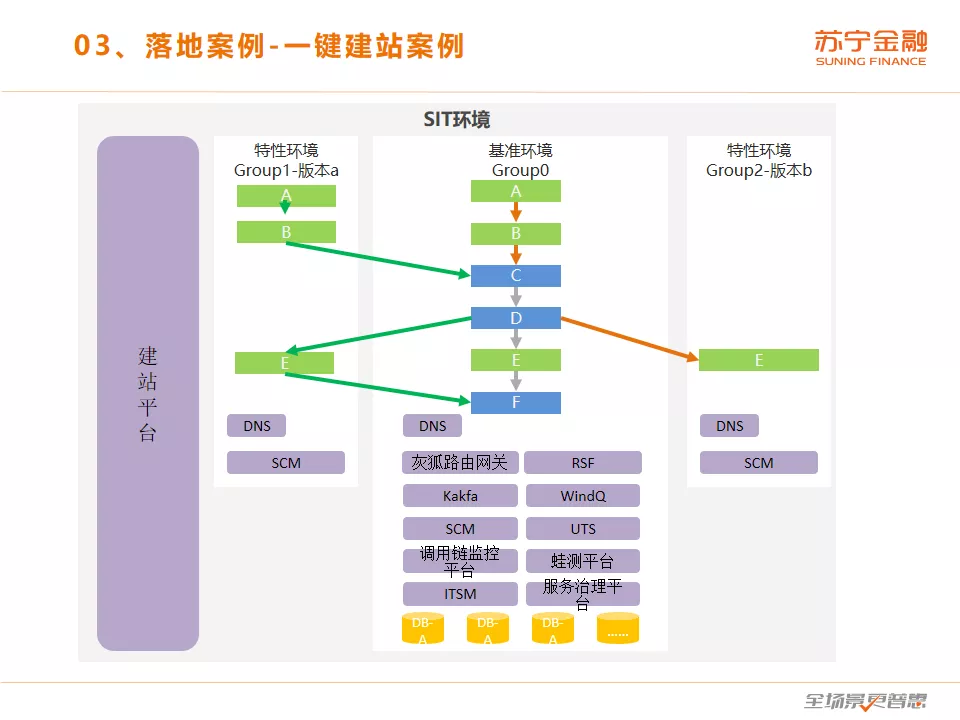
一键建站目前正在做第二阶段,第一阶段做的是一键拉起整个站点,但是这样消耗的硬件成本比较大。目前二阶段做的是轻量级建站,就是这个模型。跟前面刘超老师的方案不同,我们除了配置管理系统、DNS 服务外,数据库等中间件都是放在基准环境的。这个案例比较有挑战是双向的路由,单向路由指的是从特性环境到路由环境,这种比较简单,因为是多对一。比较难的是从基准环境,再找到原来的特性环境,这是一对多。图中有三个环境,基准环境,两个特性环境,我们在技术上也是采用了类似于刘超老师说的流量染色的原理,不过刘超老师是从网关开始染,我们不太一样,我们会用多种路由因子组合计算,比如分组标识,又或者从客户端开始的染色标识。

关于一键建站产品的价值,一个是提升并行研发能力,这是最核心的,它可以提升交付速度、提升公司的业务竞争力。第二个节约人力成本,建一套环境需要耗费大量人力资源,使用一键建站可以用复制的方式快速交付环境、节约人力资源。第三个是节约硬件资源,按需搭建,资源复用。第四个是提升测试效率,我们过程中开发了很多测试工具,例如挡板工具、测试数据银行等。

最后是如何从 0-1 打造一支 AIOps 的团队。
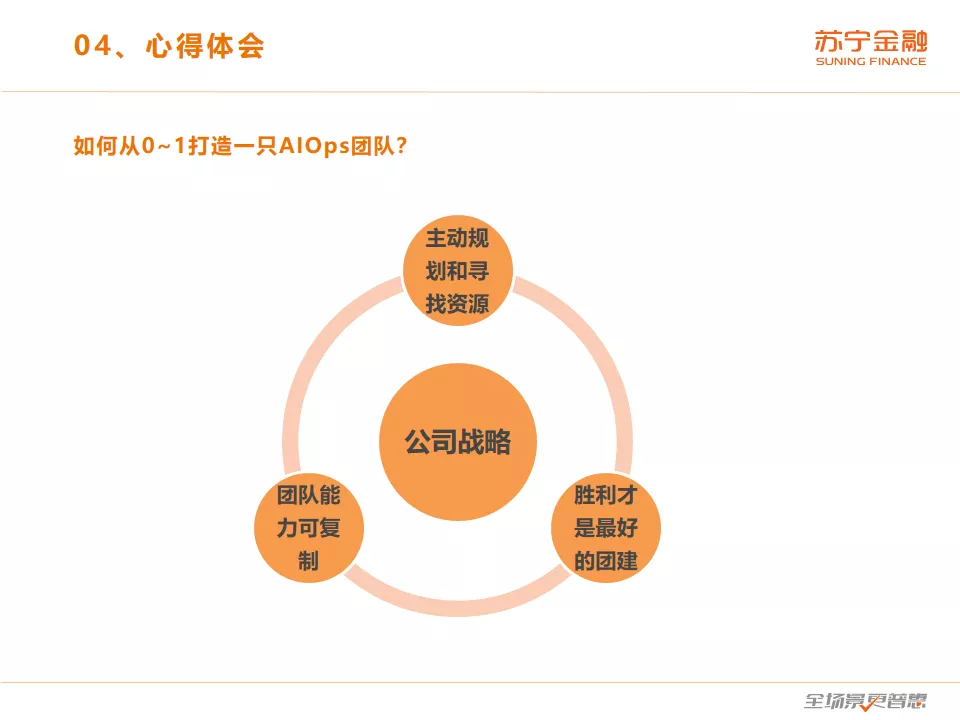
最根本的是要聚焦公司的战略,而团队的规划一定要和公司的战略合拍,比如说团队做 AIOps,绝对不适合在 2011 年的时候开始做,那个时候最核心的是业务的发展,那个时候我们做技术运营,只要能够支撑当时的业务体量就好了。堡垒机 + Zabbix 就可以搞定了,而现在这个阶段做 AIOps 就比较符合公司的战略需要。
其次我们要根据公司的战略主动规划和寻找资源,而不是被动等待。例如开发小组人力不足怎么办?这个时候应该主动去规划:我要做 AIOps,我要为公司这么大的业务体量提供技术支撑,我需要几个 AIOps 架构师,我需要几个算法专家,这个时候跟领导主动申请相关资源,只要提的要求符合公司的发展战略,公司一定会同意。
然后 “胜利才是最好的团建”,团建最好的方法就是带领团队不断取得胜利。我们做 AIOps 是从一些容易开始并且应用价值高的场景入手,用快速迭代的方式以最低的成本进行验证。公司领导对我们取得的成果,做的事情非常支持,我们也向公司要激励,慢慢把团队建起来。另外我们也参加了一些外部的比赛,比如 2019 年的 AIOps 国际挑战赛我们进了前十,比同期参赛的阿里、腾讯队伍还高,这也是一种激励。
最后是能力要可复制,因为团队人员毕竟会有流失,战斗力会下降。如果来一个新人能够快速地融入团队,能够快速把能力复制给新人,这才是一个成熟团队的标志。
再下一步如何发展,又要回到公司战略,我们要根据公司的战略看,下一步公司发展我们需要提供什么样的支撑,做什么样的事,再次进行主动规划,这是一个良性循环。

最后聊一下未来愿景,这个大厅是我们公司双十一大促的监控大厅,里面可以坐 500 个人,每次大促公司在技术保障上面投入的人力非常多,所以我们的愿景是以后一个人、一台电脑、一杯咖啡可以搞定 27W+ 的系统,谢谢!
PS:我们团队现在也在招聘 AIOps 的架构师,还有算法架构师,大家有兴趣可以联系我。最后欢迎大家来苏宁易购购物,使用苏宁金融的贷款、理财和支付产品,谢谢!
关于作者

孙 捷
苏宁易购集团
金融研发中心技术总监
曾先后任职于 IBM 和苏宁金融,对 DevOps 和 AIOps 技术平台有深入的了解,擅长相关领域的产品设计和架构设计。
设计过多款行业领先的 DevOps 和 AIOps 产品,并荣获数项相关专利;此外在开发管理、人才培养、团队建设等方面也颇有研究。



